Building Data Science Platforms – A Solution for Powercor
 Office of Naval Research -
"120630-N-PO203-241"
Office of Naval Research -
"120630-N-PO203-241"
On Thursday 8th, September 2016 I gave a talk on Powercor’s data-science platform at the AGL-Office Melbourne Data-Science Meetup. The talk briefly covered how the architecture of the platform was conceived and how the platform was implemented. Below is an excerpt from my talk to give some insight into building a platform that can handle the rigour of data modelling and analysis.
My presentation was the last section of a three-part presentation by some of the members of the team at PowerCor that helped put together the data-science platform, research, design, and implementations. The other speakers were Peter McTaggart and Adel Foda with an introduction by Jonathan Chang.
You can find the same content on the Silverpond blog.
Platform
Problems → Think → Enlightenment → Build → Solution
Problems
If you aim to build a data-science platform you are primarily motivated to enable and facilitate doing data science. This generally means that you want to be able to run models and perform analysis over your organisation’s data at scale and at speed. Although scale and speed are the constraints that immediately jump out, they are by no means the only factors that will determine the success of such a platform. All of the following will be critical to the construction, uptake, maintenance, operation, and further development of a data-science platform:
- Reproducibility
- Scalability
- Historicity
- Interoperability
- Portability
- Longevity
- Comprehensibility
- Tractability
- Sensitivity
Why are these aspects significant?
They can be thought of as requirements. Without each one a platform is untenable.
Think
Factoring and Reduction of Problems
Although the requirements as stated are all individually important, they are not orthogonal. There are various factors for success that can be tackled individually that should allow all of the requirements to be addressed. After enough navel-gazing, these principles emerge:
- Encapsulation
- Idempotency / Repeatability
- Purity
- Compositionality
Enlightenment
Build Systems ~ Functions
The conclusion we can draw from these factored requirements is that
we essentially want a build-system. If you’re familiar with make
then you’ll know what I’m talking about. On top of this, the system
should be as simple as possible - Ideally being able to be conceptually
represented with a pure function:
result = function( arguments )
There are several arguments that are common for all models running on the platform:
report = build( data-collected-to-date, date-range-of-query, …)
With the additional argument being model-specific. For example:
field-inspection-priorities = rank-faults( data, 2014-2015, threshold → 1ohm )
With this concept at the heart of our platform, compositionality becomes the enabling factor of construction and reuse.
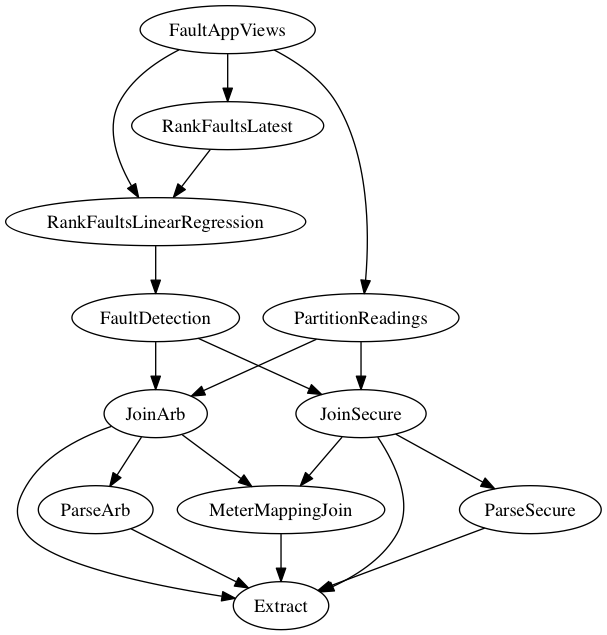
With such a methodology at play, many of the traditional pain-points such as synchronization-issues, difficulties running reports over “new-historical” data, caching, work-distribution, and validation simplify greatly, or evaporate entirely.
Solution
A solution obviously doesn’t exist in a purely conceptual space however, and there is a lot of work required to actually engineer the architecture that enables such theoretical principles. At Powercor we adopted a layered-architecture to provide different “contexts” for implementation of the platform:
- Environment
- System
- Controller
- Pipeline
- Task
- Cluster
- Boundary
- Process
This not-only provided clarity surrounding what each piece of development was mandated to interact with, but also leveraged the expertise and roles within the team so that each individual could focus on their own work and trust that the boundaries were codified with enough rigour that their work and the work of their colleagues would play nicely together. Thus the roles of data-scientist, infrastructure-engineer, platform-engineer, tester, and tech-lead were kept as focused and clearly-defined as possible.
The components that allowed us to build such contextual layers looked like the following:
| Cloud Platform | AWS |
| Data Storage | AWS S3 |
| Data-Event Propagation | AWS SQS / Apache Kafka |
| Distributed Computation | Apache Spark / AWS EMR |
| SQL Data-Query Interface | Apache Drill |
| Container Execution | Docker / Docker-Swarm |
| Data Dependency Resolution | Luigi |
| Interactive Exploratory Environment | Zeppelin |
| Metadata Storage | Postgres |
| Infrastructure Automation | Ansible |
| Version Control | BitBucket |
| Internal Applications | Internal |
Illuminated
The project was a successful collaboration between Powercor, Silverpond, and Peter, to create a new platform for a powerful data-science capability within the business. This result was achieved in a short time-span and with Powercor’s data, enabled deeper understandings than were previously within reach.
Thanks to Powercor and Peter for the opportunity to share our collaboration, as well as Data Science Melbourne and AGL for hosting a fantastic event.